希尔排序(插入排序的改良版)
在希尔排序出现之前,计算机界普遍存在“排序算法不可能突破O(n2)”的观点。希尔排序是第一个突破O(n2)的排序算法,它是简单插入排序的改进版。希尔排序的提出,主要基于以下两点:
- 插入排序算法在数组基本有序的情况下,可以近似达到O(n)复杂度,效率极高。
- 但插入排序每次只能将数据移动一位,在数组较大且基本无序的情况下性能会迅速恶化。
算法描述
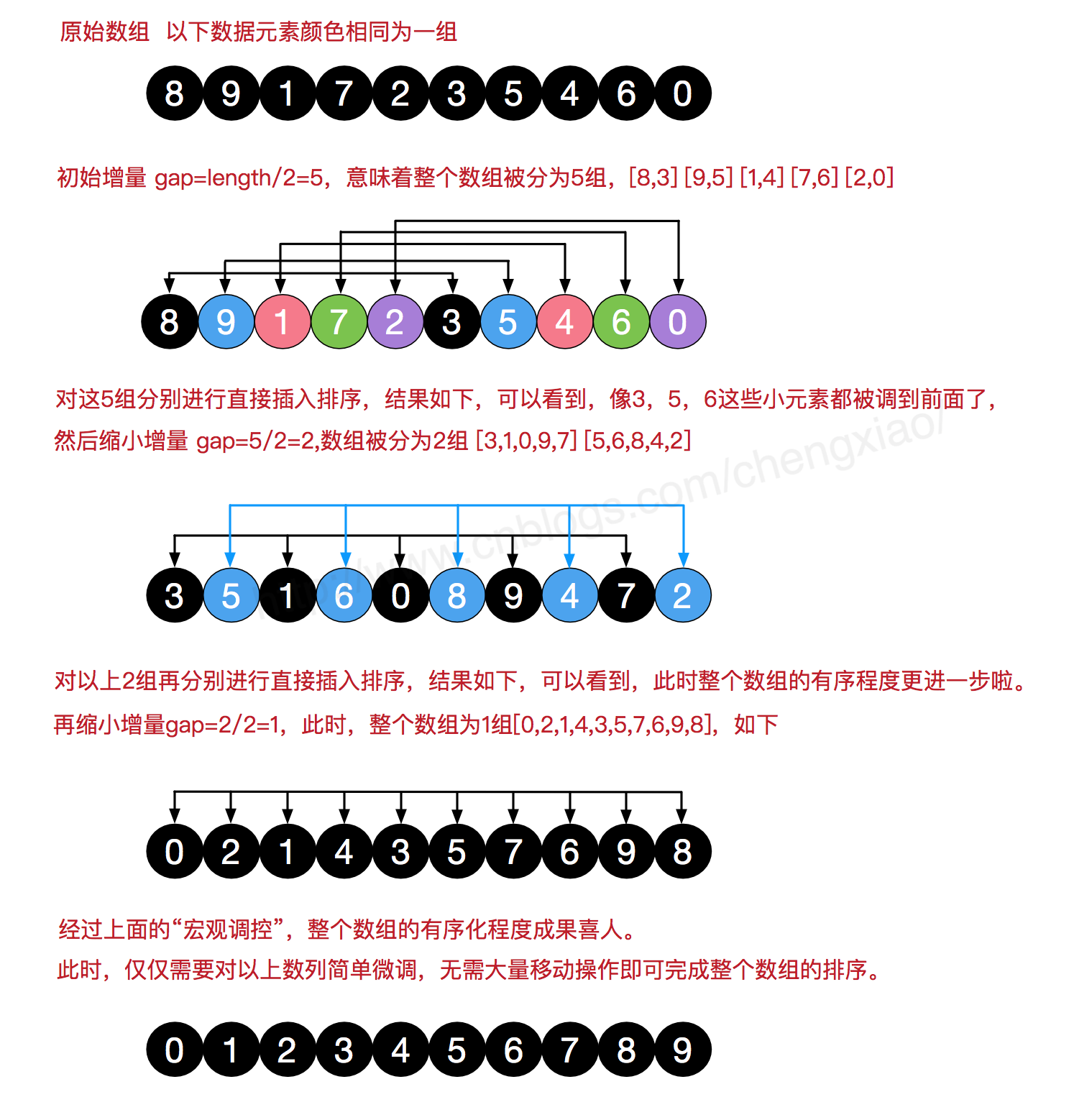
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行 k 趟排序
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度
动图演示
算法实现
在希尔排序的理解时,我们倾向于对于每一个分组,逐组进行处理,但在代码实现中,我们可以不用这么按部就班地处理完一组再调转回来处理下一组,实现时不用循环按组处理,我们可以从第gap个元素开始,逐个跨组处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
void shellSort(int arr[], int len){
for(int delta = len / 2; delta >0; delta /= 2){
for(int i = delta; i<len;i++){
int pos = i;
int curVal = arr[i];
while(pos >= delta && arr[pos-delta] > curVal){
arr[pos] = arr[pos-delta];
pos-=delta;
}
arr[pos] = curVal;
}
}
}
|
算法特点
- 希尔排序的增量数列可以任取,需要的唯一条件是最后一个一定为1(因为要保证按1有序)
- Donald Shell提出的增量,即折半降低直到1,其时间复杂度还是O(n2)。Hibbard经过复杂证明可使得最坏时间复杂度为O(n3/2)
- Shell排序不是一个稳定的算法
快速排序
快速排序算法知名度较高,对于大数据具有优秀的排序性能和相对简单的算法实现。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
算法描述
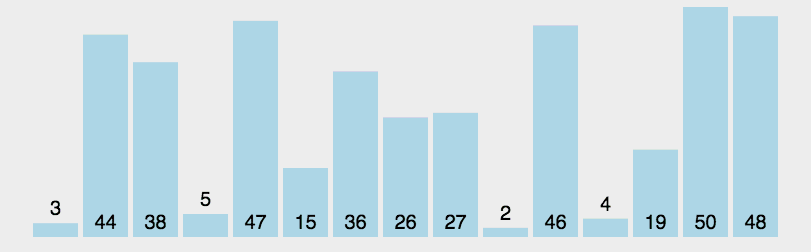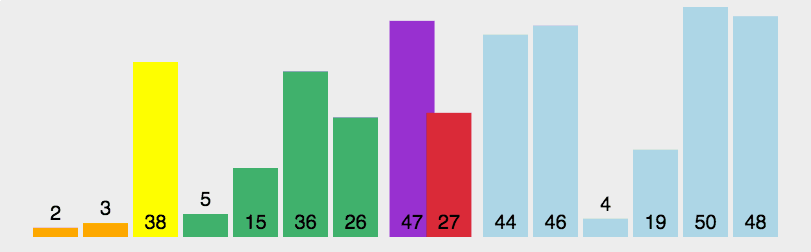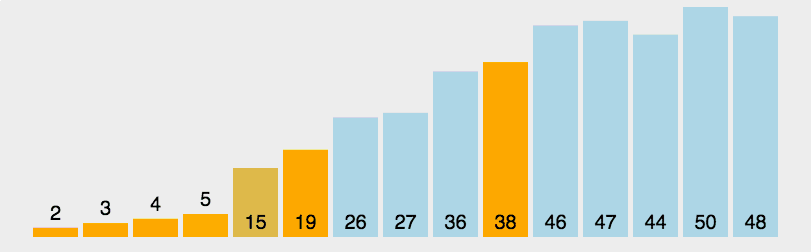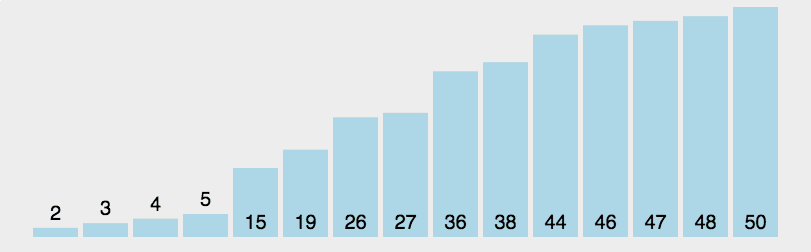
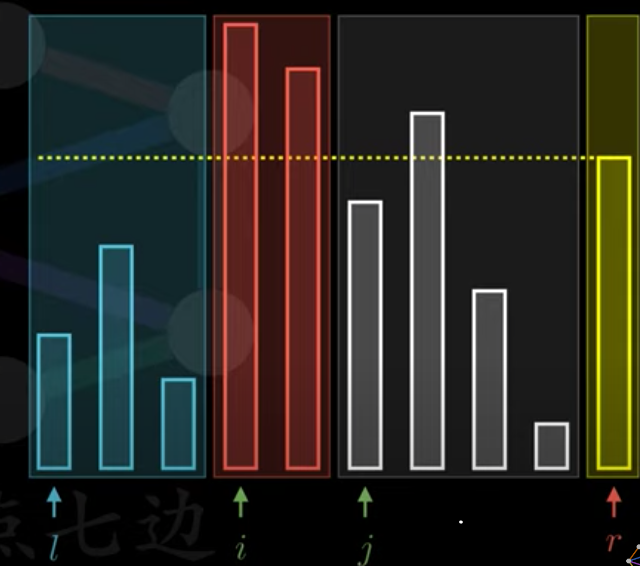
- 从序列中挑出一个元素作为基准(pivot)
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归的把左右两边的字序列进行排序
- 直到子数组长度为1
动图演示
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
| void quickSort(int arr[],int left,int right){
if(left >= right)
return;
int pivotIndex = partition(arr,left,right);
quickSort(arr,left,pivotIndex-1);
quickSort(arr,pivotIndex,right);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| int partition(int arr[],int left,int right){
int pivot = arr[left];
while(left <right){
while(left <right && arr[right] >=pivot)
--right;
arr[left] = arr[right];
while(left <right && arr[left] <=pivot)
++left;
arr[right] = arr[left];
arr[left] = pivot;
return left;
}
}
int partition(int arr[],int left,int right){
int pivot = arr[right];
int i = left;
for(int j = left;j < right;j++){
if(arr[j] <= pivot){
swap(arr[i],arr[j]);
i++;
}
}
swap(arr[i],arr[right]);
return i;
}
|
算法特点
- 快速排序并不是稳定的。这是因为我们无法保证相等的数据按顺序被扫描到和按顺序存放
- 在最坏状况下时间复杂度(顺序数列)则需要 Ο(n2),平均Ο(nlogn)
归并排序
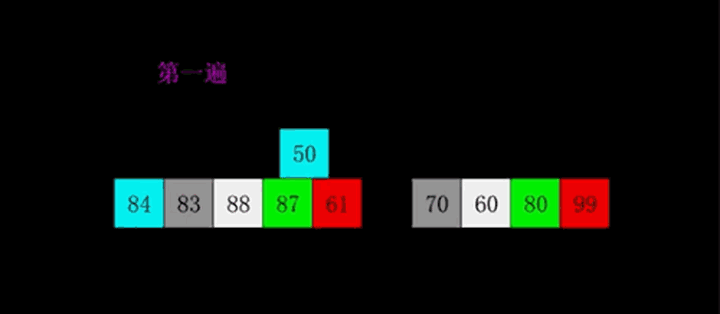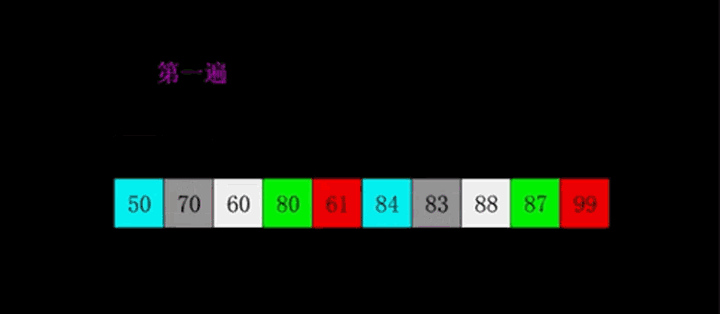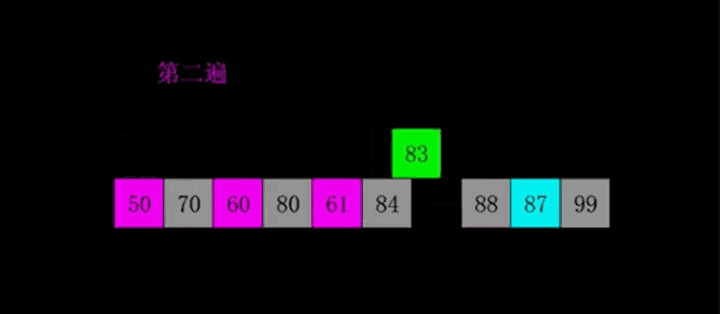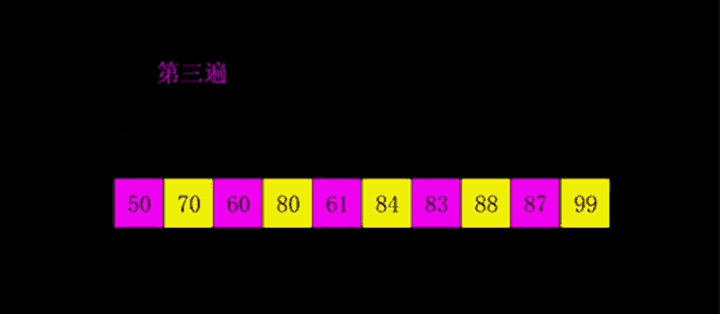
算法描述
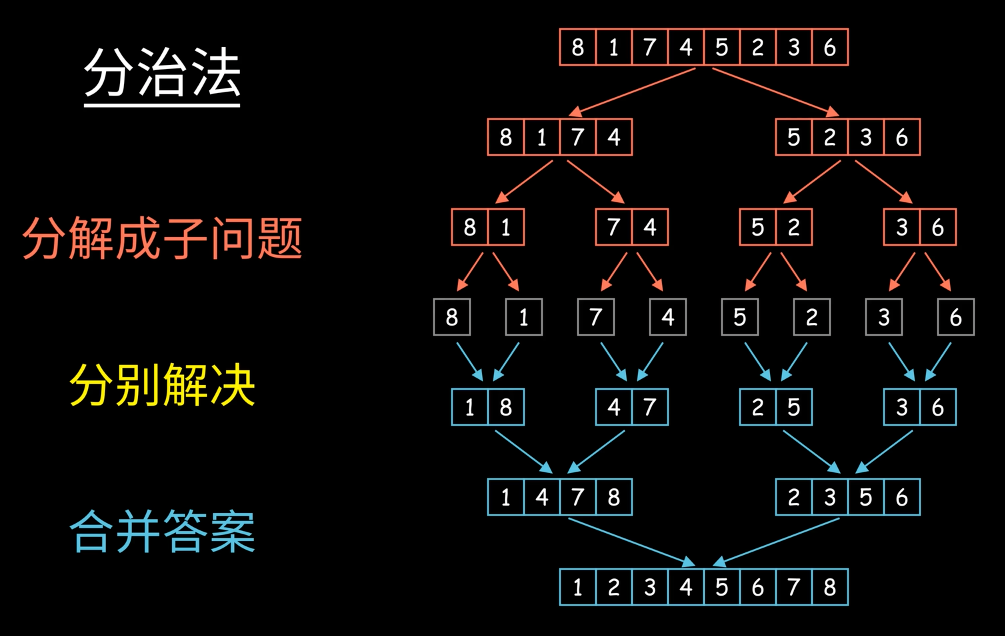
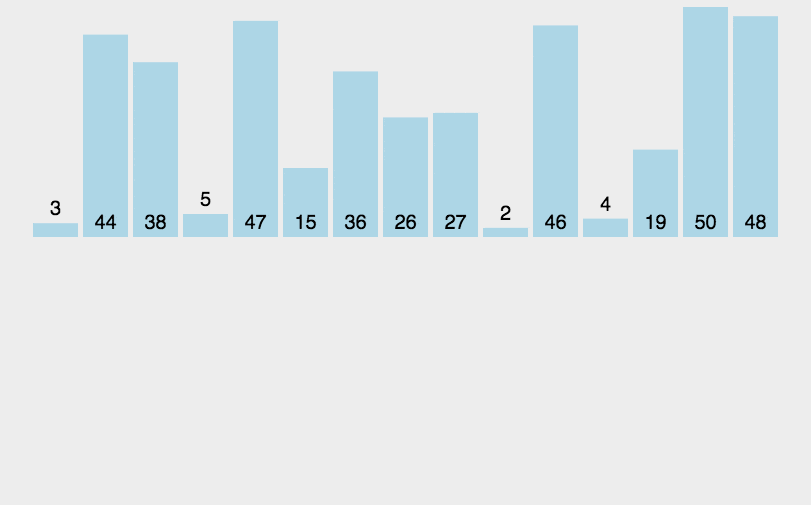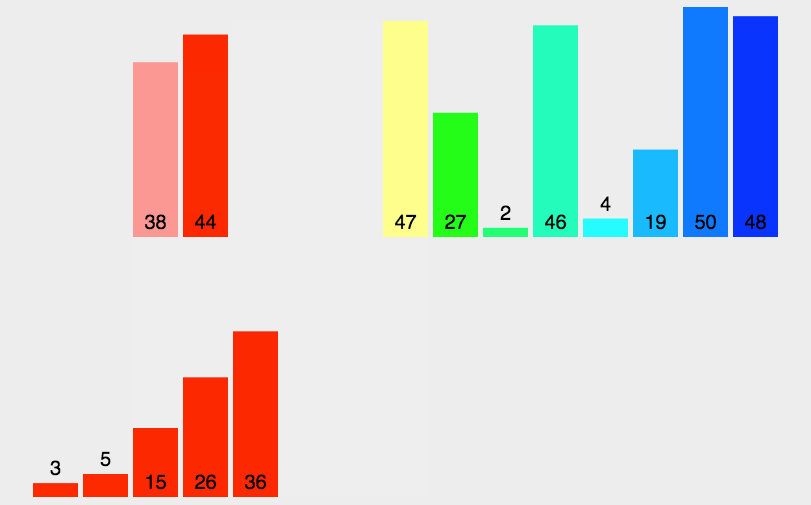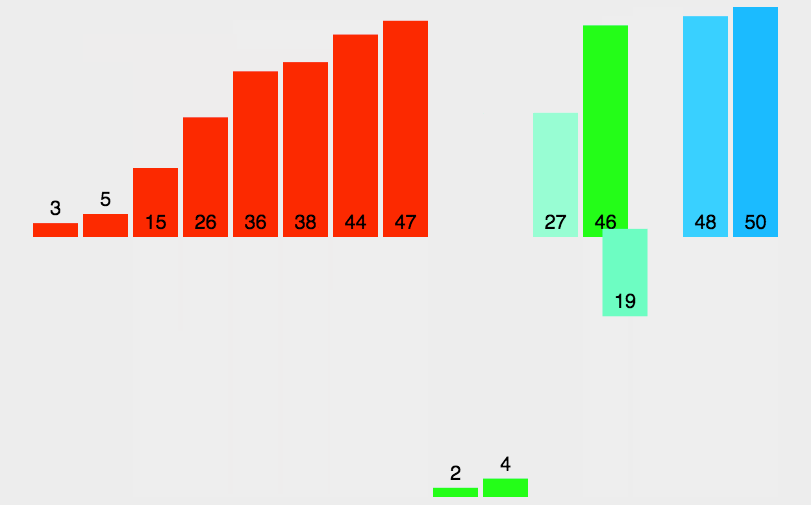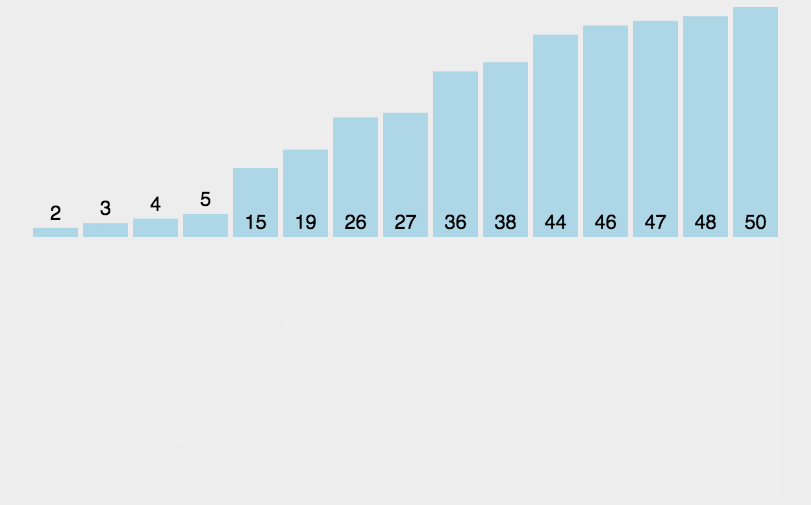
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
动图演示
算法实现
数组排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| void mergeSort(int arr[],int left,int right){
if(left >= right)
return;
int mid = left + (right-left) /2;
mergeSort(arr,left,mid);
mergeSort(arr,mid+1,right);
merge(arr,left,mid,right);
}
void merge(int arr[],int left,int mid,int right){
int *p = new int[right-left+1];
int i = left,j = mid+1;
int k = 0;
while(i<=mid && j<=right){
p[k++] = arr[i] <= arr[j] ? arr[i++] : arr[j++];
}
while (i <=mid){
p[k++] = arr[i++];
}
while ( j<=right){
p[k++] = arr[j++];
}
for(int i = left;i<=right;i++){
arr[i] = p[i-left];
}
delete []p;
}
|
链表归并排序
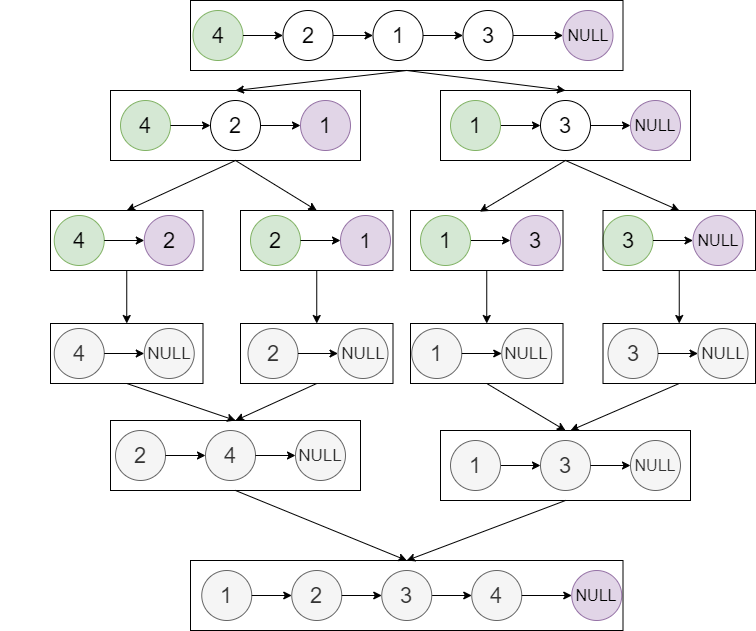
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
ListNode* sortList(ListNode* head) {
return mergeSort(head,nullptr);
}
ListNode* mergeSort(ListNode* head,ListNode* tail){
if(!head)
return head;
if(head->next == tail){
head->next = nullptr;
return head;
}
ListNode* slow = head,*fast =head,*mid = head;
while(fast != tail){
slow = slow->next;
fast = fast->next;
if(fast != tail)
fast = fast->next;
}
mid = slow;
return merge(mergeSort(head,mid),mergeSort(mid,tail));
}
ListNode* merge(ListNode* list1,ListNode* list2){
ListNode* dummyHead = new ListNode(0);
ListNode* pre = dummyHead;
while(list1 && list2){
if(list1->val < list2->val){
pre->next = list1;
list1 = list1->next;
}else{
pre->next = list2;
list2 = list2->next;
}
pre = pre->next;
}
if(list1){
pre->next = list1;
}else{
pre->next = list2;
}
return dummyHead->next;
}
|
算法特点
- 时间复杂度平均Ο(nlogn),对于数组需要O(n)的空间复杂度,对于链表只需要O(1)
- 常用于给链表排序
- 因为我们在遇到相等的数据的时候必然是按顺序“抄写”到辅助数组上的,所以,归并排序同样是稳定算法。